
Новый кластеризатор семантических ядер от Serpstat
Привет! Я уже давно и плодотворно занимаюсь сбором семантических ядер (кстати, здесь вы можете заказать качественное семантическое ядро), у меня есть семантики, которые помогают мне в разгребании портянок фраз, но я всё равно продолжаю поиск наиболее эффективного и наименее трудо- и деньгозатратного инструмента для кластеризации СЯ.
Я уже писал большую статью про кластеризацию семантических ядер и про разные методы разгруппировки, в том числе и автоматические, но сегодня я хочу подробно остановиться на кластеризаторе от Serpstat, т.к. разработчики заявляют, что они чуть ли не революцию на рынке устроили своим инструментом. Смотрим, что же на самом деле получилось…
Содержание статьи:
Кластеризаторов много, но есть ли качественный?
Серпстат – это мощный агрегатор всевозможных сеошных сервисов в одном месте. С помощью Serpstat можно сделать:
- SEO-аудит сайта;
- анализ ссылок;
- анализ ключевых слов;
- мониторить позиции;
- и ещё вагон и маленькая тележка функций.
Теперь ко всем этим инструментам добавился сервис – автоматический кластеризатор семантического ядра.
На самом деле, на рынке существует довольно много различных сервисов, которые предоставляют данную функцию. Лично я пользовался:
- TopVisor (платный сервис).
- KeyAssort (платная программа).
- ru (бесплатный сервис).
- ppc-panel.ru (бесплатный сервис).
- Сontentmonster (бесплатный сервис).
Как видите, список не малый (и это только то чем пользовался я, есть ещё множество других Rush Analytics, например, и ещё с десяток аналогов), но почему же при таком обилии автоматических группировщиков я до сих пор использую живых семантиков, которые сутками не видя солнечного света сидят в подвале (шучу, не в подвале….. в погребе 🙂 ) и работая за чашку тсампы (шучу, хер знает что они там едят 🙂 ) раскидывают по группам тысячи ключей? Почему же при таком изобилии на рынке, продолжают появляться новые кластеризаторы СЯ?
Один ответ вытекает из другого, потому что имеющиеся автоматические программы не удовлетворяют требованиям семантиков. Ни один имеющийся сервис не приблизился даже на половину к тому качеству разгруппировки, которое достигается благодаря ручной кластеризации.
И вот по этой причине всё новые и новые разработчики, шлифуя алгоритмы, выпускают на рынок «убийц» конкурентов, но всё это время по-настоящему революционного инструмента выпущено не было. Что же изменилось с приходом Serpstat’a? Об этом ниже.
Кластеризатор СЯ от Serpstat – революция на рынке семантики! (на самом деле нет)
Подробную информацию об алгоритме и особенностях инструмента от Serpstat вы можете узнать из видео:
А также для особо любопытных рекомендую ознакомиться с этой статьёй.
На самом деле подход, который реализовали серпстатовцы очень интересный. В отличие от конкурентов, которые за основу берут ВЧ ключ и составляют группы, в зависимости от пересечений в выдаче, опираясь только на него, Serpstat пошёл дальше и стал учитывать пересечения в выдаче с использованием сразу нескольких запросов. Благодаря этому группы собираются наиболее точно, уменьшается количество мелких групп, а объединение происходит наиболее качественно.
Так говорится в видео и статье, но так не происходит в реальности.
Задумка крутая, но вот реализация пока так себе. Я делаю скидку на то, что сервис ещё в beta-версии, я надеюсь, что когда он заработает на полную мощь, то реально приблизится к тем теоретическим выкладкам, о которых говорят и пишут разрабы в видео и статье. Сейчас же сервис не сильно отличается от аналогов перечисленных выше, хотя и некоторые объединённые группы меня действительно порадовали и даже в некоторых случаях удивили качеством совмещённых фраз.
Ниже на примере покажу, как группирует СерпСтатовский кластеризатор, ведь без примера все, что я написал – вода.
Пример кластеризации Serpstat
На момент тестирования сервиса у меня как раз были не разобраны несколько групп для информационного сайта по пикапу.
Я вообще специализируюсь больше на инфосайтах и поэтому в качестве первичных настроек я выбрал наиболее щадящий режим в Serpstat’e – Weak+Soft. Данный режим предусматривает объединение фраз даже при малом пересечении URL в выдаче, что собственно и нужно для информационных сайтов.
Нет надобности дробить ключи на мелкие группки для создания большого количества карточек товаров, которые отличаются по каким-то мелким параметрам – моя задача объединить все более менее схожие фразы в один кластер, чтобы будущая статья давала наиболее полный ответ.

Здесь стоит отметить, что в отличие ото всех других автоматических кластеризаторов семантических ядер, у Serpstat не один вариант объединения в виде Hard и Soft, а два. К привычному хардсофту добавился Weak и Strong. Кстати, при этом пропала возможность устанавливать так называемую «силу кластеризации», видимо её место занял вейкстронг. Подробно про все настройки можно прочитать в Блоге компании, я думаю, нет смысла мне рерайтить их информацию, все кому интересно возьмут инфу оттуда, ссылку приводил выше.
Итак, я загрузил для начала группу на 200+ ключей и стал ждать чуда. Чуда, к слову, не произошло, потому что по несчастливому стечению обстоятельств (Юпитер был в созвездии Скорпиона со всеми вытекающими 🙂 ) именно в этот день, час и минуту барахлил сервак (о чём мне сообщила любезная тех. поддержка) и поэтому пришлось ждать разгруппировку 200 несчастных ключей в течение почти часа.
Я был крайне огорчён такой продолжительностью, в голове уже появились мысли о недельных сроках обработки стандартных ядер на 15 000 – 20 000 ключевых фраз 🙂
Но как оказалось зря я нагнетал негатив, причиной реально стал косяк сервера и, когда я скормил Великому Кластеризатору 1000+ ключей по рекомендациям всё той же любезной тех. поддержки, то кучу объединенных групп он выплюнул буквально через 10 минут. А вот дальше самое интересное…
Крутые группы
На выходе я получил большое количество кластеров, среди которых были настоящие жемчужины, но их, к сожалению, было совсем немного.
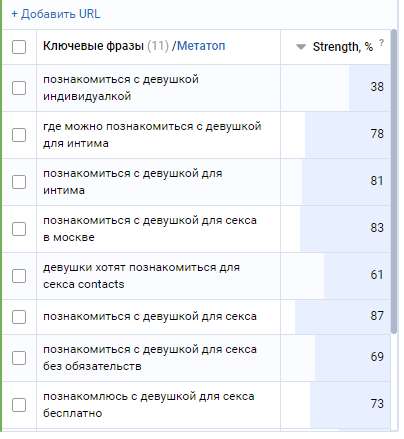

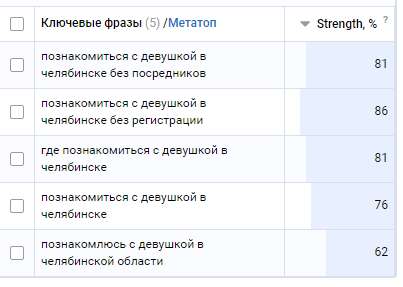
Учитывая, что ядро было очень грязное, я не чистил его от некоторых не нужных брендов и гео-запросов, результат меня порадовал.
Смешные группы
В голосину орал с запросов, объединенных в один кластер.

Толи алгоритм сексист, толи кого-то из разработчиков отшила спортсменка, и он добавил в алгоритм такую «пасхалку», но факт остаётся фактом, для кластеризатора – это очень близкие запросы, судя по оценкам 0,8-1 в последнем столбце.
Шлак-группы
А вот за исключением не большого процента годных и смИщных групп, подавляющее большинство оказалось шлаком. Очень много мелких групп по 2-3 запроса, которые с лёгкостью можно было объединить между собой, но вместо этого алгоритм посчитал их разными.

Работа по объединению всех разрозненных микро-групп займёт столько же времени, что и ручная группировка ядра с нуля.
Вывод
В общем и целом, пока инструмент от Serpstat работает не очень, особенно учитывая тарифную сетку (адекватный тариф начинается с $69 в месяц), получается дорохо, но отнюдь не бохато.
Как и у конкурентов, алгоритм работает довольно коряво, не понимает элементарных вещей и не объединяет очевидные фразы. Тем не менее, иногда он преподносит сюрпризы в виде мастерски сгруппированных кластеров, где соединены такие фразы, которые, казалось бы, мог объединить только человек.
Будем надеяться, что такие «сюрпризы» на самом деле и есть тот распиаренный алгоритм, и в будущем, после окончательной шлифовки, сюрпризом будут именно «недокластеры» типа «волосатых женщин» объединенных со «спортсменками».




Спасибо команде Serpstat за новый кластеризатор семантических ядер! Это действительно полезный инструмент, который значительно упростит нашу работу с SEO. Очень приятно видеть такие новшества, которые помогают оптимизировать процессы и делать их более эффективными.